Ollama
概览
OPL 数据空间可以很方便地接入并管理你的 Ollama 实例。本指南将带你完成连接设置、模型管理和基本使用。
面向协议的设计
OPL 数据空间采用 面向协议(Protocol-Oriented) 的设计。当我们说支持 “Ollama” 时,实际上指的是 Ollama API 协议,通常运行在 11434 端口。
某些工具可能提供了基础兼容,但这个连接类型是围绕 Ollama 的特性优化的,比如原生模型管理,以及在管理员界面里直接拉取模型。
如果你的后端本质上更接近 OpenAI 标准接口,比如 LocalAI 或 Docker Model Runner,建议改用 OpenAI 兼容服务指南,体验会更稳定。
第 1 步:建立 Ollama 连接
OPL 数据空间安装并启动后,会自动尝试连接本机的 Ollama 实例。如果一切正常,你可以立刻开始管理和使用模型。
如果连接失败,最常见原因是网络配置不正确。可以参考我们的连接排障指南。
第 2 步:管理你的 Ollama 实例
在 OPL 数据空间中管理 Ollama 的方式如下:
- 打开 管理设置。
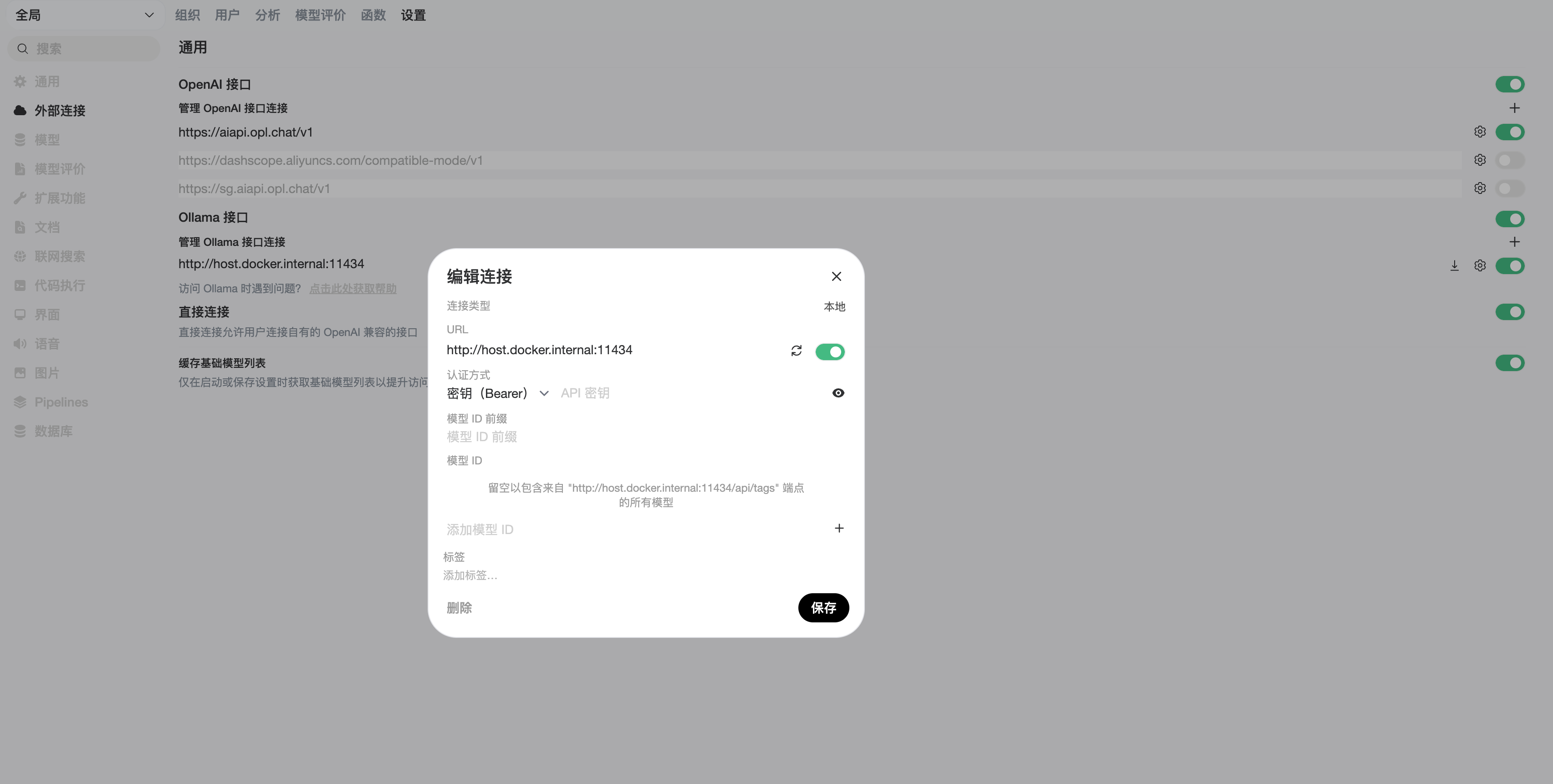
- 前往 连接 > Ollama > 管理,点击扳手图标。
- 在这里你可以下载模型、修改设置,并管理与 Ollama 的连接。
连接提示
- Docker 用户:如果 Ollama 运行在宿主机上,URL 使用
http://host.docker.internal:11434。 - 负载均衡:你可以添加 多个 Ollama 实例。 OPL 数据空间会使用 随机选择 方式分发请求,从而提供基础负载均衡。
- 注意:要让多个实例中的同名模型合并显示,Model IDs 必须完全一致。如果你使用了 Prefix ID,也要保持一致或留空。
高级配置
- Prefix ID:如果多个 Ollama 实例都提供相同的模型名,可以加前缀,例如
remote/,以便区分。 - Model IDs (Filter):通过白名单只展示部分模型;留空则显示全部。
当你连接多个 Ollama 实例,尤其是跨网络时,如果某个端点不可达,模型列表加载可能会变慢。可以通过以下方式缩短超时:
AIOHTTP_CLIENT_TIMEOUT_MODEL_LIST=3如果你保存了不可达 URL,导致设置界面难以进入,请查看 模型列表加载问题。
以下是管理界面的示意:
更快下载模型的方法
如果你想更快开始使用,也可以直接在 模型选择器 中下载模型。只要输入模型名,如果本地还没有, OPL 数据空间会提示你从 Ollama 拉取。
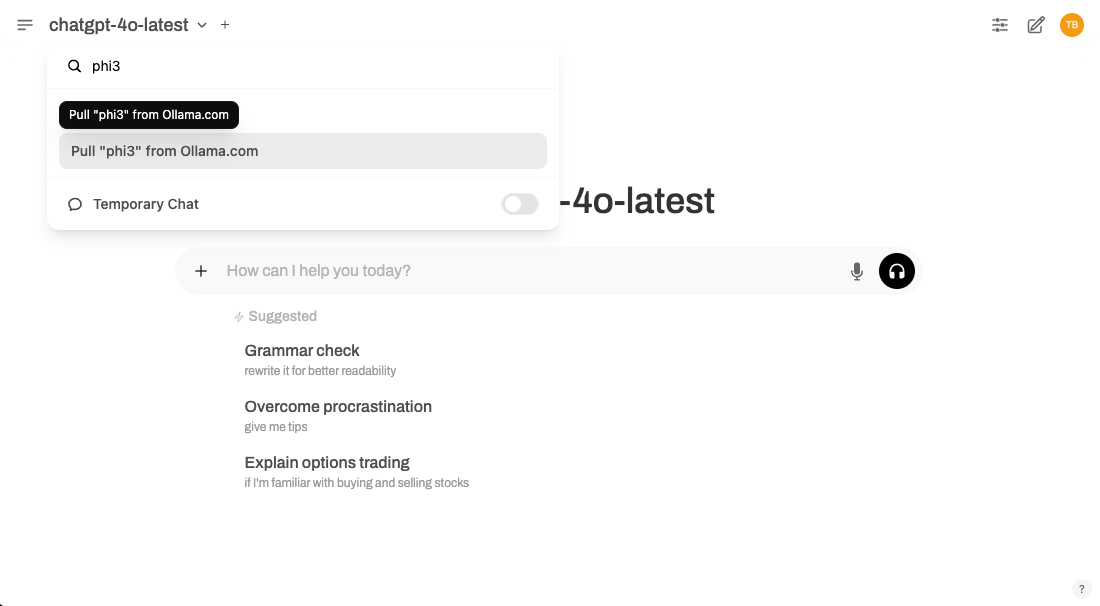
这种方式适合跳过管理员设置,直接进入聊天使用。
使用推理 / Thinking 模型
如果你使用的是 DeepSeek-R1、Qwen3 之类会在 <think>...</think> 中输出思考内容的模型,需要给 Ollama 配置 reasoning parser,才能在 OPL 数据空间中正确展示。
配置 reasoning parser
启动 Ollama 时加上 --reasoning-parser 参数:
ollama serve --reasoning-parser deepseek_r1这样思考内容会与最终答案分离,并在 OPL 数据空间中以可折叠区域显示。
deepseek_r1 解析器通常也适用于 Qwen3 等大多数推理模型。如果展示异常,请参考 推理与 Thinking 模型指南。
完成
配置好连接并下载模型后,你就可以开始在 OPL 数据空间中使用 Ollama 了。无论是试新模型还是管理已有模型,整个流程都会比较顺手。
如果遇到问题,可以查看故障排查。