外部搜索
注意
本教程为社区贡献内容,不属于 OPL 数据空间团队的官方支持范围。它主要演示如何按你的具体场景定制 OPL 数据空间。若想参与贡献,请查看贡献指南。
提示
关于 Web Search 相关环境变量的完整列表,包括并发、返回结果数量等,�请参阅 环境配置文档。
Troubleshooting
如果 Web Search 出现问题,请先查看 Web Search 故障排查指南,里面覆盖了代理配置、连接超时、空内容等常见问题。
External Web Search API
这个选项允许你把 OPL 数据空间接到自托管网页搜索 API 上,适合这些场景:
- 接入 OPL 数据空间暂未原生支持的搜索引擎
- 实现自己的搜索逻辑、过滤规则或结果处理
- 使用私有或内网搜索索引
OPL 数据空间侧配置
- 打开 OPL 数据空间
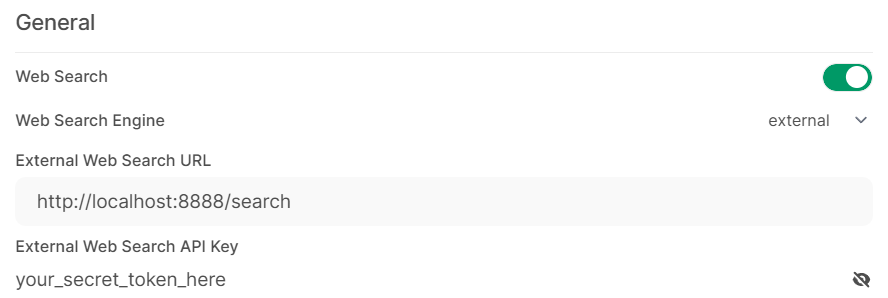
管理员面板 - 进入
设置→Web Search - 启用
Enable Web Search - 将
Web Search Engine设为external - 在
External Search URL中填写你的自定义搜索 API URL,例如http://localhost:8000/search - 在
External Search API Key中填写访问该接口所需的密钥;如果端点不要求鉴权,可留空,但不建议用于公网接口 - 点击
Save
API 规范
OPL 数据空间会按以下方式调用 External Search URL:
- Method:
POST - Headers:
Content-Type: application/jsonAuthorization: Bearer <YOUR_EXTERNAL_SEARCH_API_KEY>
- Request Body(JSON):
{
"query": "The user's search query string",
"count": 5
}-
query:用户搜索词 -
count:希望返回的最大结果数量;你的 API 可以视情况返回更少结果 -
期望的响应体(JSON):
[
{
"link": "URL of the search result",
"title": "Title of the search result page",
"snippet": "A brief description or snippet from the search result page"
}
]每个结果对象应包含:
link:结果链接title:网页标题snippet:与查询相关的摘要文本
若发生错误或查无结果,建议直接返回空数组 []。
示例实现(Python / FastAPI)
下面是一个基于 FastAPI 和 duckduckgo-search 的简化示例:
import uvicorn
from fastapi import FastAPI, Header, Body, HTTPException
from pydantic import BaseModel
from duckduckgo_search import DDGS
EXPECTED_BEARER_TOKEN = "your_secret_token_here"
app = FastAPI()
class SearchRequest(BaseModel):
query: str
count: int
class SearchResult(BaseModel):
link: str
title: str | None
snippet: str | None
@app.post("/search")
async def external_search(
search_request: SearchRequest = Body(...),
authorization: str | None = Header(None),
):
expected_auth_header = f"Bearer {EXPECTED_BEARER_TOKEN}"
if authorization != expected_auth_header:
raise HTTPException(status_code=401, detail="Unauthorized")
query, count = search_request.query, search_request.count
results = []
try:
with DDGS() as ddgs:
search_results = ddgs.text(
query, safesearch="moderate", max_results=count, backend="lite"
)
results = [
SearchResult(
link=result["href"],
title=result.get("title"),
snippet=result.get("body"),
)
for result in search_results
]
except Exception as e:
print(f"Error during DuckDuckGo search: {e}")
return results
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8888)